Microsoft recently unveiled the Phi 3 family of Small Language Models, offering users a choice between 4K and 128K context windows. The latest release includes the 3.8 billion parameter model, now accessible via Hugging Faces and Azure platforms.
In a landscape where new models emerge frequently only to fade into obscurity shortly after, the Phi 3 series distinguishes itself with notable achievements:
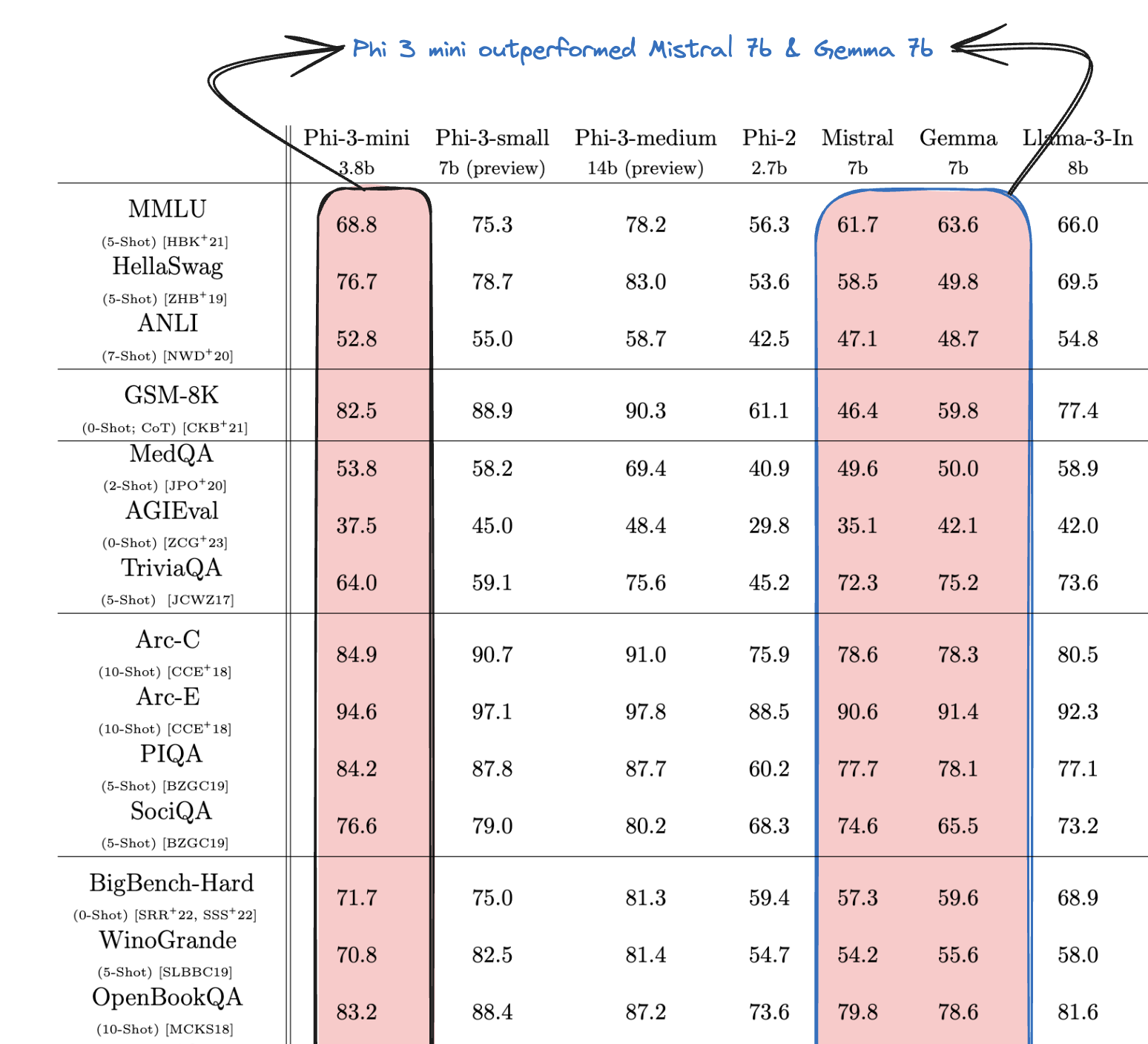
- The Phi 3 Mini, with mere 3.8 billion parameters, surpassed larger models like Gemma 7b and Mistral 7b across various benchmarks.
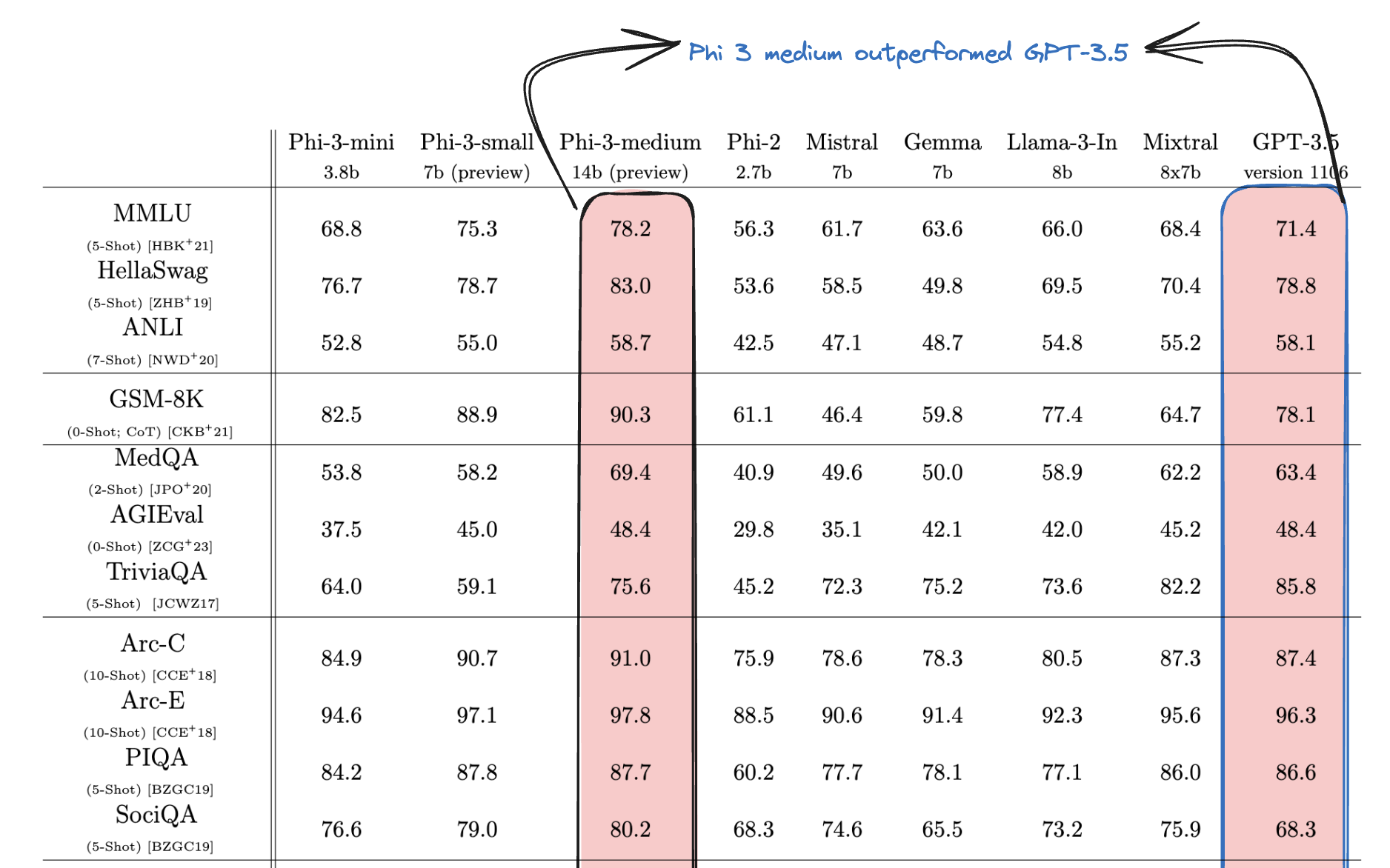
- Remarkably, the phi-3-medium model outperformed Chat GPT-3.5 in numerous benchmarks, despite having significantly fewer parameters (14 billion compared to GPT-3.5’s 175 billion).
This exceptional performance is owed to a strategic approach to training data, which involved leveraging children’s books. Traditionally, large language models have relied on vast amounts of internet data for training. However, Microsoft’s researchers opted for a different strategy.
They created a specialized dataset called “TinyStories” consisting of 3,000 words, and tasked a large language model with generating children’s stories using specific word combinations(one noun, one verb and one adjective). This novel approach yielded promising results, with the model producing fluent narratives.
Building on this success, researchers curated publicly available educational data to train Phi-1, employing a sophisticated prompting and filtering methodology. This process, culminating in the creation of the “CodeTextbook” dataset, ensured high-quality synthetic data for training the Phi models.
Choosing right-size language model for the task
But even small language models trained on high quality data have limitations. They are not designed for in-depth knowledge retrieval, where large language models excel due to their greater capacity and training using much larger data sets.
LLMs are better than SLMs at complex reasoning over large amounts of information due to their size and processing power.
Unlike their larger counterparts, small language models (SLMs) like Phi 3 are not designed for comprehensive knowledge retrieval. However, they excel in tasks such as summarisation, content generation for Sales & Marketing teams, and basic customer support queries.
While SLMs may not replace large language models entirely, they offer distinct advantages, particularly in edge computing scenarios. Understanding the strengths and limitations of these models is crucial for leveraging them effectively in various applications.